我们打开东方财富网站:http://quote.eastmoney.com/stocklist.html
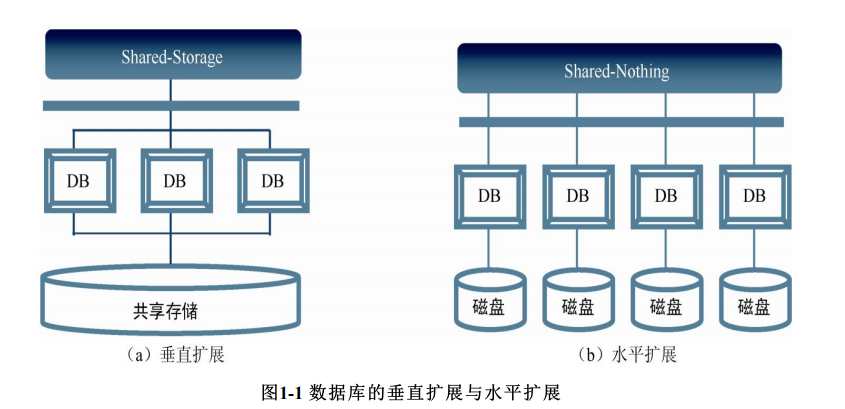
假如懒得爬,也可以用现成的股票数据源:https://stockapi.com.cn
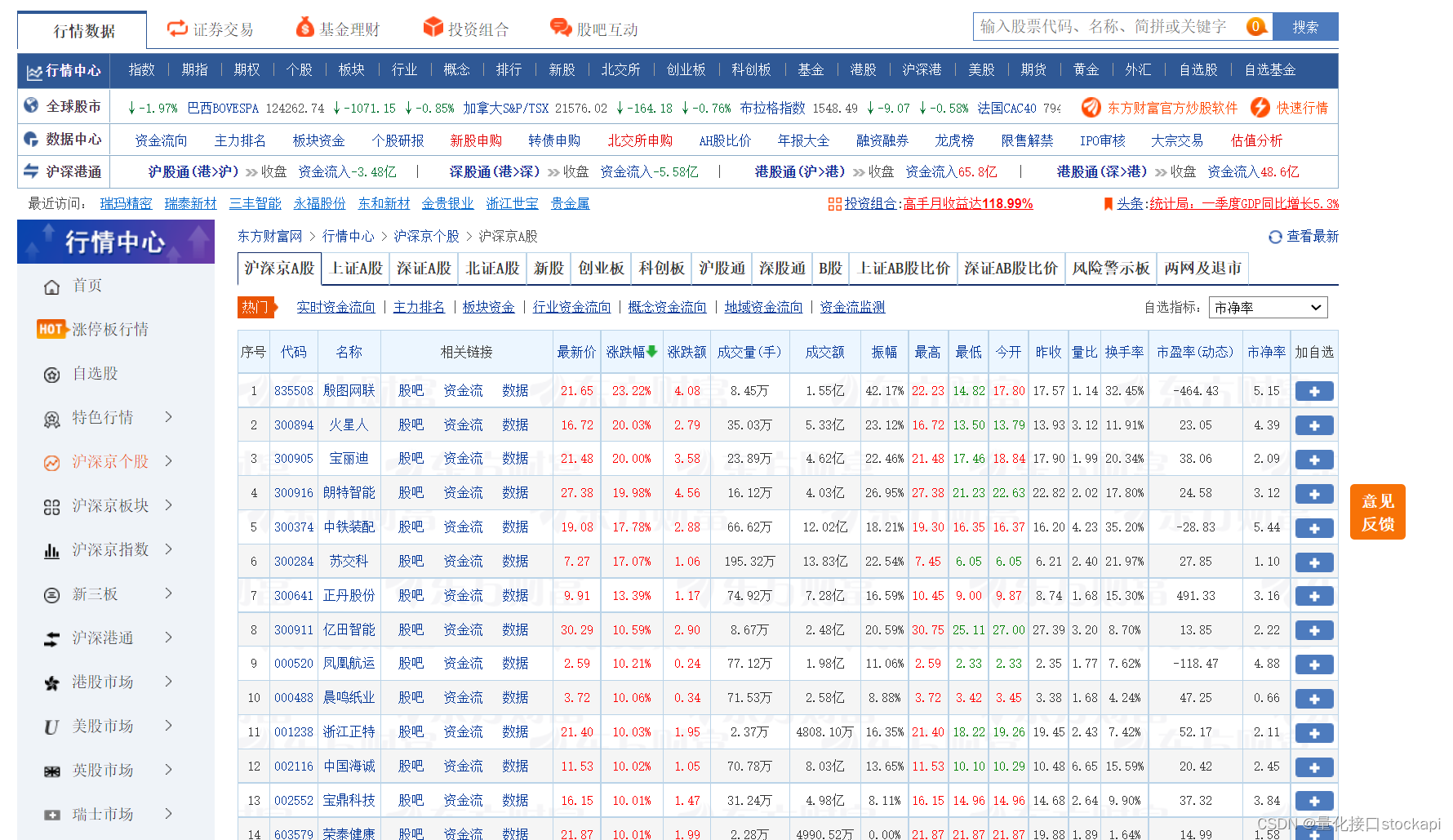
这展示了所有股票信息,不过需要我们分页去爬取
我们可以查询具体的html代码:
<div class="stock-info" data-spm="2">
<div class="stock-bets">
<h1>
<a class="bets-name" href="/stock/sz300388.html">
国祯环保 (<span>300388</span>)
</a>
<span class="state f-up">已休市 2017-09-29 15:00:03
</span>
</h1>
<div class="price s-stop ">
<strong class="_close">--</strong>
<span>--</span>
<span>--</span>
</div>
<div class="bets-content">
<div class="line1">
<dl><dt>今开</dt><dd class="">19.92</dd></dl>
<dl><dt>成交量</dt><dd>8917手</dd></dl>
<dl><dt>最高</dt><dd class="s-up">20.15</dd></dl>
<dl><dt>涨停</dt><dd class="s-up">21.96</dd></dl>
<dl><dt>内盘</dt><dd>4974手</dd></dl>
<dl><dt>成交额</dt><dd>1786.10万</dd></dl>
<dl><dt>委比</dt><dd>-50.69%</dd></dl>
<dl><dt>流通市值</dt><dd>59.98亿</dd></dl>
<dl><dt class="mt-1">市盈率<sup>MRQ</sup></dt><dd>50.59</dd></dl>
<dl><dt>每股收益</dt><dd>0.20</dd></dl>
<dl><dt>总股本</dt><dd>3.06亿</dd></dl>
<div class="clear"></div>
</div>
<div class="line2">
<dl><dt>昨收</dt><dd>19.96</dd></dl>
<dl><dt>换手率</dt><dd>0.30%</dd></dl>
<dl><dt>最低</dt><dd class="s-down">19.92</dd>
</dl>
<dl><dt>跌停</dt><dd class="s-down">
17.96</dd></dl>
<dl><dt>外盘</dt><dd>3943手</dd></dl>
<dl><dt>振幅</dt><dd>1.15%</dd></dl>
<dl><dt>量比</dt><dd>0.11</dd></dl>
<dl><dt>总市值</dt><dd>61.35亿</dd></dl>
<dl><dt>市净率</dt><dd>3.91</dd></dl>
<dl><dt>每股净资产</dt><dd>5.14</dd></dl>
<dl><dt>流通股本</dt><dd>2.99亿</dd></dl>
</div>
<div class="clear"></div>
</div>
</div>
发现股票名称在class="bets-name"的a标签中,其他的数据都在dt和dd标签中
import requests
from bs4 import BeautifulSoup
import re
#优化,可以减少程序判断编码所花费的时间
def getHTMLText(url, code='UTF-8'):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(url, stockList):
html = getHTMLText(url, 'GB2312')
soup = BeautifulSoup(html, 'html.parser')
aInformaton = soup.find_all('a')
for ainfo in aInformaton:
try:
stockList.append(re.findall(r'[s][hz]\d{6}', ainfo.attrs['href'])[0])
except:
continue
def getStockInformation(detailUrl, outputFile, stockList):
count = 0
for name in stockList:
count = count + 1
stockUrl = detailUrl + name + '.html'
html = getHTMLText(stockUrl)
try:
if html == "":
continue
stockDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockinfo = soup.find('div', attrs={'class': 'stock-bets'})
stockname = stockinfo.find('a', attrs={'class': 'bets-name'})
# 当标签内部还有标签时,利用text可以得到正确的文字,利用string可能会产生None
stockDict["股票名称"] = stockname.text.split()[0]
stockKey = stockinfo.find_all('dt')
stockValue = stockinfo.find_all('dd')
for i in range(len(stockKey)):
stockDict[stockKey[i].string] = stockValue[i].string
#\r移动到行首,end=""不进行换行
print("\r{:5.2f}%".format((count / len(stockList) * 100)), end='')
#追加写模式'a'
f = open(outputFile, 'a')
f.write(str(stockDict) + '\n')
f.close()
except:
print("{:5.2f}%".format((count / len(stockList) * 100)), end='')
continue
def main():
listUrl = 'http://quote.eastmoney.com/stocklist.html'
detailUrl = 'https://gupiao.baidu.com/stock/'
outputFile = 'C:/Users/Administrator/Desktop/out.txt'
stockList = []
getStockList(listUrl, stockList)
getStockInformation(detailUrl, outputFile, stockList)
main()
方法2.采用Scrapy框架和正则表达式库
(1)建立工程和Spider模板(保存为stocks.py文件)
在命令行中进入:E:\PythonProject\BaiduStocks
输入:scrapy startproject BaiduStocks 建立了scrapy工程
输入:scrapy genspider stocks baidu.com 建立spider模板,baidu.com是指爬虫限定的爬取域名,在stocks.py文件删去即可
(2)编写spider爬虫(即stocks.py文件)
采用css选择器,可以返回选择的标签元素,通过方法extract()可以提取标签元素为字符串从而实现匹配正则表达式的处理
正则表达式详解:
<a class="bets-name" href="/stock/sz300388.html">
国祯环保 (<span>300388</span>)
</a>
re.findall(‘.(‘, stockname)[0].split()[0] + ‘(’+re.findall(’>.<’, stockname)[0][1:-1]+‘)’
匹配结果:国祯环保(300388)
因为’('为正则表达式语法里的基本符号,所以需要转义
正则表达式从每行开始匹配,匹配之后返回[’ 国祯环保 ('],采用split将空白字符分割,返回[‘国祯环保’,‘(’]
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = ['http://quote.eastmoney.com/stocklist.html']
def parse(self, response):
fo=open(r'E:\PythonProject\BaiduStocks\oo.txt','a')
#fo.write(str(response.css('a').extract()))
count=0
for href in response.css('a').extract():
try:
if count == 300:
break
count=count+1
stockname=re.findall(r'[s][hz]\d{6}',href)[0]
stockurl='https://gupiao.baidu.com/stock/' + stockname + '.html'
#fo.write(stockurl)
yield scrapy.Request(url= stockurl,headers={"User-Agent":"Chrome/10"} ,callback=self.stock_parse)
except:
continue
pass
def stock_parse(self,response):
ffo=open(r'E:\PythonProject\BaiduStocks\stockparse.txt','a')
stockDict={}
#提取标签中class="stock-bets"的标签元素
stockinfo=response.css('.stock-bets')
#将提取出来的标签转化为字符串列表,然后取第一个
stockname=stockinfo.css('.bets-name').extract()[0]
#ffo.write(stockname)
keyList=stockinfo.css('dt').extract()
#ffo.write(str(keyList))
valueList=stockinfo.css('dd').extract()
stockDict['股票名称'] = re.findall('.*\(', stockname)[0].split()[0] + '('+re.findall('\>.*\<', stockname)[0][1:-1]+')'
for i in range(len(keyList)):
stockkey=re.findall(r'>.*</dt>',keyList[i])[0][1:-5]
stockvalue=re.findall(r'>.*</dd>',valueList[i])[0][1:-5]
stockDict[stockkey]=stockvalue
yield stockDict
(3)编写PipeLine(即pipelines.py文件)
系统自动生成了Item处理类BaiduStocksPipeline,我们不采用系统生成,新建一个BaiduStocksinfoPipeline类,并书写Item处理函数
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksinfoPipeline(object):
#爬虫打开时执行
def open_spider(self,spider):
self.f=open(r'E:\PythonProject\BaiduStocks\BaiduStocks\asdqwe.txt','a')
# 爬虫关闭时执行
def close_spider(self,spider):
self.f.close()
#处理Item项
def process_item(self,item,spider):
try:
self.f.write(str(item)+'\n')
except:
pass
return item
此时要修改配置文件setting.py文件
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksinfoPipeline': 300,
}
(4)运行爬虫:scrapy crawl stocks